基本类型
这个类型是按照projectExplorer中来划分的
-
Audio(音频对象)
-
Event(事件)
-
SundBank
-
GameSyncs
基本结构
Audio
声音对象(Actor-Mixer Hierarchy)
它可以是语音(Sound Voice),也可以是音效(Sound SFX)。每个声音对象都包含一个源。这个源在wwise中有两种:音频源和插件源。
Sound Voice:这个是用于对白
Sound SFX:这个是用于Actor-Mixer Hierarchy内所有其他声音
音频源:是一个独立层次,将导入的音频文件和声音对象分割开来。音频源链接到导入到工程中的音频文件。
分组
将不同的声音对象编为一组,就能统一设置整个组的属性和行为了。
- 用Container(容器)来按照特定行为(随机,顺序或者切换等)来播放一组对象。
- Actor-Mixer(角色混音器)通常用来设定一组的整体属性(音量,音高)。
Container处于Actor-Mixer Hierarchy中的第二层级,可以说它们是父对象和子对象。可以使用容器来为声音和其他容器进行分组。通过在容器内“嵌套”容器,可以得到多样化的结果,模拟真实声音表现。
Actor-Mixer它比容器高一个层次。也可以说,Actor-Mixer可以是容器的父对象,但反之不可以的。Actor-Mixer可以是任意数量的声音,容器以及其他Actor-Mixer的父对象。
容器
鉴于游戏中的音频需要按照不同行为播放,可以选择不同的Container类型:Random(随机),Sequence(序列),Switch(切换)和Blend(混合)。
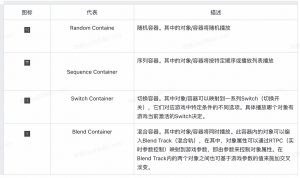
- 随机播放容器:可以进行标准随机选择,也可以进行洗牌选择,还能为随机容器内的每个对象指派一个权重值。
- 随机和序列播放都包含多个对象,所以必须得指定播放模式
- Step-每次播放容器时,仅播放容器内的一个对象。
- Continuous-每次播放容器时,会完整播放容器内的所有对象。
- 由于可能有多个游戏对象使用同一容器,因此需要决定游戏中一个容器的所有实例是作为一个对象处理,还是单个实例单独处理。
- Global全局-将游戏内使用的所有该容器作为一个对象进行处理,因此可以针对所有游戏对象避免重复声音或者语音对象。
- Game object游戏对象-将该容器的各个实例最为单独实体进行处理。即不会在所有游戏对象间共用声音内容。
- 在Switch Container中Switch或State和RTPC(实时参数控制)被用来代表各个不同条件。每个切换Switch/State/RTPC对应于与该条件有关的声音对象将会播放。
- 在Switch Container中切换变化的时候可以选择播放行为
- Play-决定是每次切换被触发时都重新播放对象,还是仅当触发的Switch/State发生变化时才重新播放。
- Across Switches-对于被指派至多个切换开关的同一对象,当触发新的Switch/State时是否继续播放。
- Fade In-触发的新的Switch/State时,新对象是否应用淡入。
- Fade Out-触发的新的Switch/State时,已有对象是否应用淡出。
- 在混合容器里可以添加:Blend Container,Random Container,Sequence Containers,声音,switch Container,Voices(语音)
- 在混合容器里可以同时播放多个对象。在Blend Track中启用交叉淡变会改变这些对象的听感和振动。
- 在使用交叉淡变过度时,需要注意以下:
- 音频文件长度必须大于或等于0.2秒,交叉变淡时间最短为0.1秒。
- 从声音A交叉变淡至声音B时,声音引擎所允许的淡变时间最长为音频文件A长度的一半。如果设置的值超过了,会自动调整到最大值。
- 如果使用RTPC设置容器的音高值,或者在播放的时候触发了Set Pitch事件动作,则对声音应用交叉变淡时可能会产生意外结果。
- 对源插件应用交叉淡变时,无法确定源的结束时间,那么淡变可能会被忽略。
- 当Switch Container作为Sequence Container的子容器时,会根据指派给切换开关的对象数量,区别应用交叉淡变过度。
- 交叉淡变期间,声音引擎会使用两个不同的声部。
- 在低于音量阈值或超过播放数量限制时,Play from Beginning和Resume虚声部行为会影响声音持续时间,这不在交叉淡变时间机制考虑范围之内。
- 当声部的音量低于阈值时,声部会变成虚声部。对于任何声音,会使用其所有音频通道的实际有效音量与阈值相比较。这个有效音量包括Actor-Mixer Hierarchy,淡变过度,互动音乐过渡,RTPC,状态,定位和衰减等所有的音量影响。
- 同时播放的流越多,要求的Pre-fetch(预取时间)越多。
- 在使用“Global”来避免声音重复,但是如果容器包含的声音数量有限,并且同时要播放很多该容器,可能会出现重复问题。所以我们要确保容器内的声音对象至少为播放实例数量的两倍。
- 在使用Blend Container播放的时候,因为该容器内的所有对象都会同时播放,因此会消耗大量内存,可以使用虚声部设置来降低CPU占用,但是如果频繁地进行短暂的交叉变淡,则可能会导致出现错误。
- Switch Container和Blend Container均可配合RTPC使用,并会产生相似的效果。如果希望在不同时间播放不同的对象,并且不需要交叉变淡,那就可以使用switch Container。如果希望一直播放所有对象,并且需要交叉变淡那就可以使用Blend Container。
输出总线(Master-Mixer Hierarchy)
总线是一种用来对工程中对象进行分组的机制,目的是管理混音和最终声音输出。可以为工程中的通路定义相对属性,状态,RTPC以及效果器。
这里有三种类型:
- Master Audio Bus(主音频总线):它决定了音频的最终输出。
- Audio Bus(音频总线):可分组在Master Audio Bus之下,以有助于组织和提供混音。可以在总线上加效果器。
- Auxiliary Bus(辅助总线):可分组到任何辅助总线或音频总线之下。可以对辅助总线应用效果器。在辅助总线中无法做闪避,HDR混音和声部调节。
Actor-Mixer Hierarchy的声音会被默认连通到Master Audio Bus,但是可以在修改到我们自己建立的总线上去。
定义总线的相对属性
相对属性是积累的,总线的属性值会累加到其下的子对象中
- Bus Volume-总线音量,用于直接调整总线的音量大小。
- Voice Volume-声部音量,总线中正在播放的音频对象所应用的衰减。
- Voice Pitch-声部音高,总线中正在播放的音频对象的播放速度。
闪避信号
在游戏的不同时刻,希望某些对象比其它对象更加突出。可以修改以下属性和行为来控制信号闪避方式:
- Ducking volume(闪避音量)
- Fade out(淡出)
- Fade in(淡入)
- Curve shape(曲线形状)
- Maximum ducking volume(最大闪避音量)
总线无法要求自己或其直接父总线闪避
定位
- 局部环境音-发声体保持在一个位置上。
- 非局部环境声音-发声体可移动,并不依附于某个特定游戏对象。
- 移动对象声音-发声体随着某个特定游戏对象一起移动。
- 游戏界面声音-此声音与特定游戏界面要素或者其它保持在屏幕固定位置上的道具相关联。
声音和音乐对象选择是否3D空间化的区别在于如何将源声道映射至输出扬声器。不空间化,那么输出声道将于源声道完全匹配。空间化,则可将各个输入声道输出至环绕声环境中的任何扬声器。在运行中可通过Positioning Type的RTPC更改定位方法。无论是否使用空间化,都提供衰减功能,即模拟音频信号在发声体原理或背离听者时的自然衰减。
虚发声体:
为了计算源对各个扬声器的声道贡献大小,“虚发声体”以半圆形状环绕听者设置。半圆的大小取决于散布(100%代表整圆,0%代表听者正前方的点)。然后将半圆划分为与声道数量相同的,大小相等的区域,源的各个原声声道都作用于指定的区域。一旦完成,将计算各个虚发声体对各个扬声器的实际贡献。
空间定位
空间化确定游戏3D环境中对象的实际位置或定位。
两种空间化:
- Position(位置):仅使用游戏对象的三维定位信息。
- Position+orientation(位置+朝向):同时使用游戏对象的三维定位和朝向信息。
三种定位类型:
- Emitter(发声体):由实时游戏位置数据来定义“发声体”游戏对象的空间定位。在选择Emitter时,WWise中所定义的传播属性将直接关联至游戏中听者和发声体的位置或朝向。
- Emitter with Automation(发声体自动化):通过在Wwise中创建路径来定义“发声体”游戏对象的空间定位。定义忽略游戏对象位置和衰减的一组固定的传播行为。
- Listener with Automation(听者自动化):通过在Wwise中创建路径来定义“听者”游戏对象的空间定位。定义忽略游戏对象位置和衰减的一组固定的传播行为。
Attenuation(衰减)
除了空间化外,还可以定义对象的衰减设置。衰减设置用于模拟当信号原理听者时的自然衰减。
衰减基于以下两个属性:
- Distance attenuation(距离衰减):根据发声体和听者之间的距离来影响信号的强度。
- Cone Attenuation(声椎衰减):根据发声体相对于听者的朝向来影响信号的强度。
距离衰减使用一系列曲线进行定义。这些曲线将距离值映射到音量等Wwise属性值。通过定义曲线各个点的属性,可以在对象远离听者时控制对象的音量衰减。
锥形衰减使用一系列夹角进行定义。这些夹角用于定义声源前方,侧方和背后的区域。通过定义声源周围的这些不同区域,可以更具游戏中的朝向来模拟对象的衰减。
Attenuation ShareSet
当游戏中的许多对象拥有相同的衰减属性,因此可以先创建一份衰减,然后使用Attenuation ShareSet在工程中的许多对象之间共享。
定义各种对象属性的衰减曲线
可以为以下Wwise属性创建衰减曲线:
- Output Bus Volume-输出总线音量。连接到音频输出总线的信号的衰减或振幅。
- Auxiliary Send Volumes-发送到游戏定义和用户定义的Auxiliary Bus的信号的衰减或振幅。
- Low-Pass filter-根据指定值来衰减高频的递归滤波器。低通滤波器的单位代表已经应用的低通滤波比例,0表示无低通滤波,100代表最大衰减。
- High-pass filter-高通滤波器。根据指定值来衰减低频的递归滤波器。高通滤波器的单位代表已应用的高通滤波比例,其中0代表无高通滤波,100代表最大衰减。
- Spread-散布。扩散到附近扬声器的音频量或百分比,以使声音能够随着距离的增加从低扩散的点声源变为完全扩散的传播源。值0表示某扬声器附件的发声体的所有声道只通过该扬声器播放。值100表示将扩散声源的声道,以便通过所有扬声器都能够听到或感觉得到。
- Focus-聚焦。百分比值,用于收缩由扩散值生成的虚拟发声器。焦距0%表示虚发声器保持不变,值越高,各个虚发声器越靠近源声道的原点。
使用锥形边界模拟方向性
在现实中声音通常具有一定的方向性。在wwise中模拟声音的方向可以使用声锥。声锥使用不同的夹角模拟声音在特定方向上的传播。当听者一道这些夹角外卖时,Output Bus Volume将衰减。
以下角定义声锥的区域:
- Inner angle:内角。此夹角定义的区域中输出总线音量不衰减,也没有低通滤波效果发生。
- Outer angle:外角。此夹角定义的区域中输出总线音量发生衰减,低通滤波效果保持在最高水平。
Output Bus Volume在过度区域中发生滚降。在无衰减发生的内角边界和达到最大衰减值的外角边界之间,使用线性插值法对音量进行衰减。在外角定义的区域中,音量衰减始终等于最大衰减值。
Speaker Panning和3D Spatialization交叉淡变
当我们需要做一种从声像摆位的环境过渡到需要空间化的环境。好比玩家在一个房间里听音乐,然后从房间走到户外,户外在播放环境音的情况。在做交叉淡变时,必须同时计算两种定位类型,因此消耗的运行时CPU资源也比只选择一种类型时更多一些。
Spread的影响
Spread的衰减曲线可以根据距离来做修改。这个距离是发声体和听者之间的距离长度。
朝向的影响
受到两种不同朝向因素的影响:
- 发声体相对位置
- 发声体相对朝向
发声体的朝向仅影响多声道声源。
Focus
Focus(聚焦)参数能够在应用旋转和扩散之前,将每个输入声道的虚声源集中在一起。在对离散多声道文件进行摆位时,Focus参数用于减少声道信号在其他输出通道中的泄漏。但是不适用于Ambisonics声像摆位,因为其设计即包含输出声道间的泄漏,尽管是均匀泄漏。因此,当声源的声道配置是Ambisonic时,将会忽略Focus值。
斜面声源在平面声道配置中的摆位
虚声源坐标在扬声器平面上的投影,用于计算摆位。
听者的旋转会影响到:
Height Spread的效果
在典型的Distance Spread曲线设计中,声源距离听者越远,使用的Spread值越小(反之亦然)。这样的话,在距离较近时,声源会像个圆;在距离较远时,就会像个点。在声源靠近时,其射入方向会突然改变,听起来可能不太自然。
在声源位于听者上方或者下方很远的位置并被摆位到2D声道上时,也会出现类似的失真。在距离较远的情况下,Spread曲线会估算出一个较小的值;这时声源若穿过听者所在平面上的路径,其声像就会从一侧突然摆位到另一侧。对此可在对象从听者上方或下方穿过时,借助四周的扬声器来对声音进行散布处理,以此在第三维度上没有扬声器的情况下传达高度的变化。
使用动画路径定义空间定位
设置预定义位置时,无论听者在游戏中的位置和朝向如何都会遵循以下情况:
- 声音将总是通过相同的扬声器播放。
- 通过相同的电机感受到振动。
使用动画路径定义定位信息。动画路径由每次定义源位置的若干个控制点构成。如果是创建了多个点后,对象则将随着时间沿着路径进行运动。
优先级
在游戏中,可以同时播放很多对象,对象的数量甚至有可能超出由项目团队设置的数量上限。为了有效管理播放对象的数量,必须规定同时最多可以播放多少个对象,已经哪些对象会被优先播放。
三个属性可以确定在游戏中将同时播放哪些对象:
- Playback limit-限制同时运行播放的对象数量(不包含虚声部)
- Playback priority-一个对象相对于另一个对象的重要性。
- Volume threshold-低于这一特定音量的对象将不会播放。
声音引擎的各个内存池设置内存阈值,当启动之后,声音引擎会定期检查所用内存百分比是否低于指定的阈值。如果超过了,将会忽略优先级比较低的声音,用来播放优先级比较高的声音。
当音量降低至音量阈值,或当声音的数量超出Playback Limit上限时,会为对象执行以下操作:
- 继续播放
- 终止
- 移至虚声部列表
虚声部列表是一种虚拟环境,在这个环境中,声音引擎会监视列表里的声音的特定参数,但不会执行声音处理。
Virtual Voices:
在决定使用哪个虚声部的设定之前,需要了解下它们的内存占用和CPU占用
- Play from beginning-该选项仅使用少量内存和CPU,但如果对声音进行了流播放,则从虚声部返回时可能存在延迟。
- Play from elapsed time-改选项可以节省部分CPU和内存,但如果流播放声音,则声音从虚声部返回的时候可能出现延迟。
- Resume-改选项使用较少的CPU,但会占用较大的内存,因为当声音从虚声部返回时将会保留内存缓冲区。
通过以下方式来管理工程内同时播放的各种对象:
- 限制每个游戏对象可播放的实例数量,或对于Actor-Mixer Hierarchy\Interactive Music Hierarchy 对象及值对象,在全局范围内限制其可以播放的实例数量。
- 限制可通过特定总线的对象;
- 限制整个游戏中的对象总数。
当在Actor-Mixer 或者Interactive Music层级设置了播放数量限制,如果子对象忽略了父级对象的Playback Limit那么子对象的数量不记录在父对象限制里;可播放的实例数量是它们的总和。
由于各个对象的优先级已经在角色混音器或者Interactive Music层上进行了指定,因此总线上不存在播放优先级设置。
Event
Wwise使用Event(事件)来驱动游戏中的声音,音乐,对话和振动。由此提供了两种Event
- 动作Event
- Dialogue events(对白事件)
动作事件包含若干个动作(Action),这些动作将指定Wwise对象是否播放,暂停,停止等。
Event中的每个动作都有相应的作用范围设定。作用范围确定Evnet动作是应用于全局所有GameObject还是触发该事件的特定GameObject。全局的GameObject的话相当于应对的是总线。
在创建动作事件后,这些事件可通过打包成SoundBank集成到游戏引擎中,在相应的条件下调用这些事件。由于游戏引擎使用名称或ID去使用,所以在创建完事件之后,就可以集成到游戏中去,之后就算进行事件内容的微调,只要名称和ID没有更改,就不需要额外的编程。
将游戏事件和Wwise中的事件进行匹配
使用SoundBank定义文件来跟踪哪些时间已经集成到游戏中,确实哪些事件以及还需要在Wwise中创建哪些事件。
以编程方式停止,暂停和恢复声音
事件信息存储在声音引擎的默认内存池中。为了避免占用默认内存池中的过多空间,可以使用SDK中的ExecuteActionOnEvent()功能,以编程方式停止,暂停和恢复声音。
Game Object
Game Object(游戏对象)是Wwise中的核心概念,因为声音引擎中被触发的每个Event都与一个GameObject相关联。Game Object通常指的是游戏中能够发出声音的特定对象或元素。
Wwise为每个GameObject 存储了各种信息:
- 与GameObject相关联的音频对象的属性偏置值,包括音量和音高。
- 3D位置和朝向
- Game Sync信息,包括State,switch和RTPC
- 环境效果
- 声障和声笼
在使用GameObject之前,程序员需要在代码中注册GameObject。
Listener
Listener(听者)在游戏中代表话筒。Listener在游戏3D空间中拥有位置和朝向。在游戏期间,Listener的坐标与GameObject的位置进行比较,以便将与GameObject相关联的3D声音指定给相应的扬声器,来模拟3D环境。
GameSyncs
在完成初步的游戏设计后,您可以开始考虑如何使用被称为 Game Sync(游戏同步体)的 Wwise 元素来串接和处理互动音频中的变化和替换行为,这些行为也是游戏内容的一部分
State
使用State可以优化声音和音乐素材,允许为同样的声音灵活创建不同的“Mixing Snapshot”(混音快照),响应游戏中的变化并改变全局属性。通过改变声音或音乐对象的属性,无需添加新素材就可以创造性地匹配各种游戏场景。
使用State
State需要隶属于StateGroup(状态组),才能供Wwise对象使用。可以按逻辑将各种State划分StateGroup来简化管理。
在同一个StateGroup内各State之间能平滑过渡,可以定义状态过渡的时长。
State可以通过两种机制集成到游戏中。一种集成机制是调用含Set State动作的事件,另一种是调用State Group和State本身。
Switch
在使用层次结构组织对象之外,Wwise中的Switch可以简化声音,音乐和振动对象的组织。Switch代表游戏中特定元素的不同条件,可以用来管理这些条件下的相应对象。将特定条件下的对象指派到特定Switch,这样播放该游戏元素时,将播放当前switch对应的对象。
将Game Parameter值映射到Switch
可以使用Game Parameter的值来驱动Switch的切换,在映射之前需要创建并定义游戏参数。
RTPC
在游戏中实现一些动态效果,可能会需要将特定对象的属性与游戏中的某些参数值绑定。在Wwise中可以使用实时参数控制(RTPC)来实现这一点。使用曲线沿线上的一系列点创建RTPC。该曲线表示Game Parameter和Wwise中音频属性之间的关系。当游戏中的Game Parameter发生变化时,Wwise使用RTPC曲线来确定相应的属性值。
对于Wwise中的对象,总线,效果器,衰减和切换开关使用RTPC。
在将RTPC作用于现有属性值的时候,最终的属性值采用以下两种方式中的一种:
- Absolute:将使用RTPC确定的值,忽略对象现有的属性值。
- Relative:RTPC确定的值将与对象的现有属性值相加。
绝对和相对设置为预先定义,无法更改。
Trigger
一种Wwise元素,跟其他Game Sync一样会被游戏调用。触发器会定义Wwise将做出怎样的特定响应来反应游戏中的情节变化。Trigger在响应游戏突发事件时,将播放Stinger(插播乐句)。Stinger是一种短乐句,它会与当前音乐叠加并混合播放,以音乐的形式来对游戏做出响应。
SoundBank
有两类Bank
- Initialization (Init) bank: 基础的init.bnk,它是初始化库。一种特殊的库,其中包含有关工程的所有通信信息,每次wwise生成SoundBank都会自动创建init.bnk。只需要在游戏开始前加载一次,就能得到游戏期间工程的所有通用信息。所以它必须得是最先加载的声音包。
- SoundBank:这个文件中同时包含事件数据,声音,音乐和振动结构数据或音频文件。它可以在需要使用内部信息的时候才加载出来,在不用的时候去卸载掉。提高平台内存的利用率。
内容
- Event data:事件数据
- structure data:声音,音乐或振动结构数据
- Media files:媒体文件
加载
- LoadBank
此方法显式加载SoundBank中的所有内容,而不验证媒体文件是否已经加载到内存。这可能导致同一媒体文件被多次加载到内存中。
- PrepareBank
用于加载SoundBank中的所有内容,此方法不是立即加载媒体文件,而是通过使用PrepareEvent()机制来将所有媒体加载到内存中。通过使用此机制加载媒体,Wwise首先查看媒体文件是否已经存在内存中,然后再加载它。这可以避免内存中出现媒体文件重复,从而将内存占用保持在最低水平。
- PrepareEvent,PrepareGameSync
在动作事件被游戏调用前,使用PrepareEvent来prepare这些事件。prepare事件时将从文件系统中加载所有被引用的媒体文件,如果所有被引用的结构元数据尚未加载,则还将从SoundBank中加载这些结构元数据,当动作事件不再需要的时候,可以将它Unprepare(接触预备),相应媒体文件于是将从内存中被清除掉。这可以避免内存中出现重复文件。
注意
使用Prepare相关的加载方式会降低媒体加载到内存中的速度。读取时间延长是因为声音引擎需要搜索磁盘。
结论
Wwise的核心由五个主要组件构成的
-
Audio object(音频对象)
-
Event(事件)
-
Game Sync(游戏同步体)
-
Game Object(游戏对象)
-
Listener(听者)
Event 和 Game Sync 是 Wwise 和游戏中都不可分割的两个组件。这两个组件在游戏中负责驱动音频,在 Wwise 的音频素材和游戏中的组件之间架起必要的桥梁。