引用https://www.c-sharpcorner.com/article/C-Sharp-heaping-vs-stacking-in-net-part-iv/
本文中我们将研究垃圾收集(GC)以及保持应用程序有效运行的一些方法
标记
让我们从GC的角度来看这件事。如果我们负责“清除垃圾”,我们需要好好设计一个方案。首先,我们需要确定什么是垃圾,什么不是垃圾。
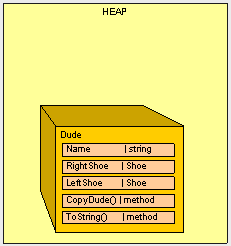
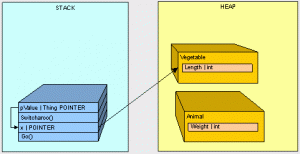
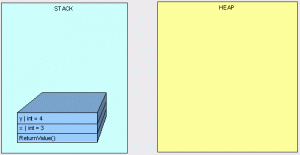
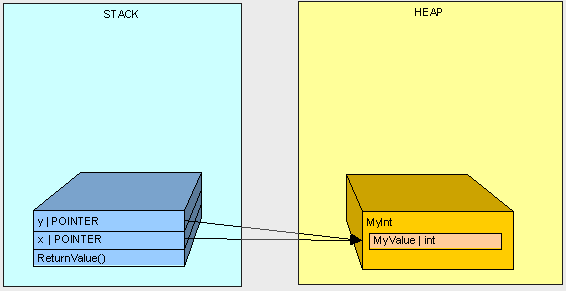
为了确定需要保留的内容,我们首先假设所有未使用的都是垃圾。想象一下,我们与两个好朋友住在一起, Joseph Ivan Thomas(JIT)和 Cindy Lorraine Richmond (CLR)。Joe和Cindy会跟踪他们在使用什么,并向我们提供他们需要保留的物品清单。我们将初始列表称为“root”列表,因为我们将其当成作用起点。我们将保留一个主列表,以图形化我们要保留的房间中所有物体的位置。使列表中的内容在正常工作时所需要的内容都添加到图表中。这也就是GC确定保留哪些内容的方式。它接受一个“Root”对象引用列表,以使其免受即时(JIT)编译器和公共语言运行时(CLR)的影响,然后递归搜索对象引用以构建应包含哪些内容的图形需要保留。
root包括:
- 全局/静态指针。通过在静态变量中保留对对象的引用来确保它不会被垃圾回收。
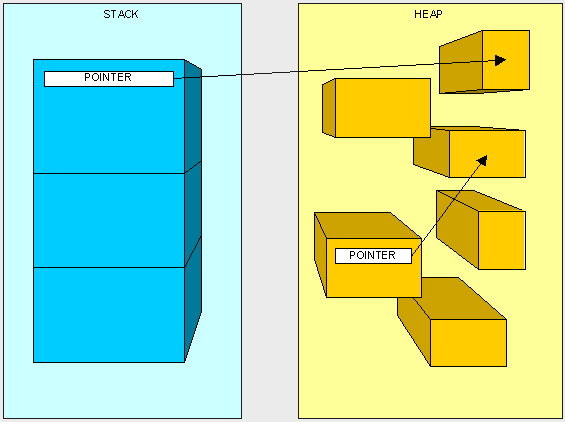
- 堆栈上的指针。我们不会想要去抛弃掉我们应用程序的线程仍然需要执行的东西。
- CPU寄存器指针。CPU中内存地址指向的托管堆中的所有内容都应该要保留下来。
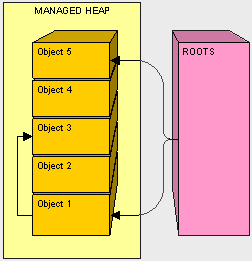
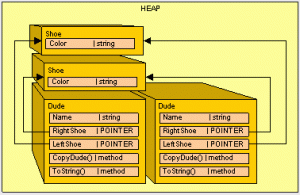
从上图我们可以看到,从roots直接引用了我们托管堆中的object1和object5,而我们的object1引用了我们的object3,所以在递归搜索中,我们roots也引用到了object3,现在我们知道所使用到的物体后,下一步进行压缩。压缩
现在我们已经标识了需要保留的物体对象,我们现在只需要移动下需要保留的对象,即可压缩空间。
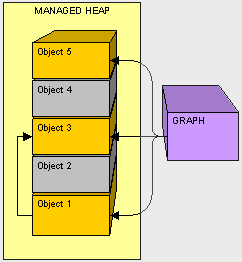
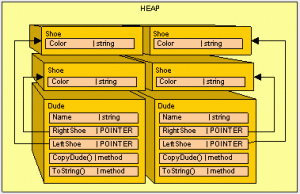
在我们的内存中,我们还不需要放置一个对象之前,我们就先清理空间,由于不需要object2,因此作为GC,我们将object3往下移动,固定在object1的附近,把object2给清理掉。
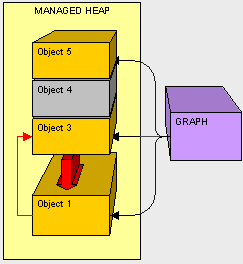
接下来我们按照和上面一样的方式,把object5给复制下来。
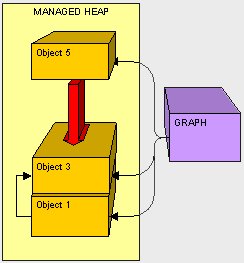
现在我们已经清理了所有的内容了,我们只需要写一个便签并将其放置在压缩堆的顶部即可让Claire知道新的对象放在哪里。
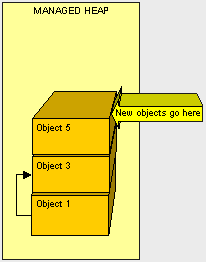
了解GC的本质可以帮助您理解,移动对象是非常消耗的。所以我们可以减少所要移动的内容的大小,那么我们将改善下GC流程,因为复制的内容将减少。处理托管堆之外的东西
作为负责垃圾收集的人,我们在打扫房间的时候遇见一个问题是如何清理掉汽车中的物体。清洁时,我们需要清洁的所有东西,如果笔记本电脑在家而电池在车里该怎么办呢?
在某些情况下,GC需要执行代码以清理非托管资源,例如文件,数据库连接,网络连接等等。一种解决方法是通过终结器class Sample{ ~Sample(){ // } }在对象创建期间,所有带有终结器的对象都将添加到终结队列中,假设object1,4,5都具有终结器的话,并且位于终结队列中。让我们看看当应用程序不再引用object2和4并且做垃圾回收时候会发生什么。
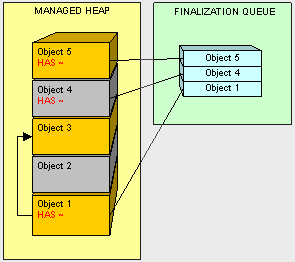
object2以通常方法处理掉,但是,当我们处理到object4的时候,GC看到它在终结队列中,然后就先不回收掉object4的所拥有的内存,而是移动object4并把它的终结器添加到名为freachable的特殊队列中。
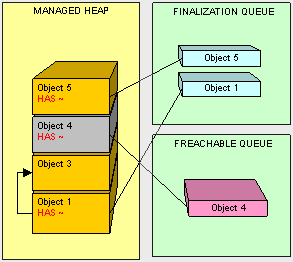
有一个专用线程用于执行freachable队列中的对象。一档终结器由对象4上的该线程执行了,它将从freachable队列中删除。然后只有这样,object4才能准备好被GC;
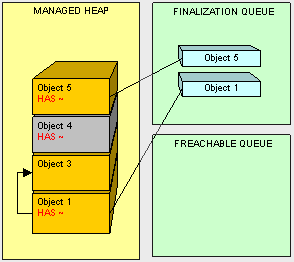
然后,object4会在下一个GC循环中被回收掉。
因此在我们的类中添加终结器会为GC增加工作量,这个消耗是非常昂贵的,并且会对垃圾回收的性能和程序产生不利的影响,仅在绝对确定需要终结器的时候才使用它们。
更好的做法是确保清理非托管资源。可以想象,最好是显式关闭链接并且使用IDisposable接口进行清理,而不是尽可能的用终结器。IDisposable
实现IDisposable的类再Dispose()方法(接口的唯一签名)中执行清除。因此如果我们有一个ResourceUser类而使用using来追踪finalizer,代码如下:
public class ResourceUser{ ~ResourceUser(){ // } }我们可以用IDisposable作为实现相同功能的更好方法:
public class ResourceUser:IDisposable{ public void Dispose(){ // } }IDisposable与using关键字集成在一起。在using块的末尾,对using()中声明的对象调用Dispose()。在using块之后不应引用该对象,因为该对象的本质上应被视为“已消失”并已准备好由GC清除。
public static void DoSomething(){ ResourceUser rec = new ResourceUser(); using(rec){ // } }还有一种写法是把对象放在using块中,这样从表面上看它更有意义,因为rec不在using块的范围以外可用。这种模式更符合IDisposible接口的意图
public static void DoSomething(){ using(ResourceUser rec = new ResourceUser()){ // } }通过using()和实现IDisposible的类一起使用,我们可以执行清理操作,而不会通过强制终结对象来增加GC的额外开销。
静态变量:当心
class Counter{ private static int s_Number = 0; public static int GetNextNumber(){ int newNumber = s_Number; s_Number = newNumber + 1; return newNumber; } }如果两个线程同时调用GetNextNumber(),并且在s_Number之前都为newNumber分配了相同的值。
则他们将返回相同的结果。word是确保一次仅一个线程可以访问代码块的一种方法。最佳的做法是:您应锁定尽可能少的代码,因为线程必须在队列中等待才能执行lock()块中的代码,并且效率低下。class Counter{ private static int s_Number = 0; public static int GetNextNumber(){ lock(typeof(Counter)){ int newNumber = s_Number; newNumber += 1; s_Number = newNumber; return newNumber; } } }静态变量当心的第二种情况
接下来,我们必须注意静态变量引用的对象。请记住,如何清理“roots”引用的任何内容。请看下面的例子:
class Olympics{ public static Collection<Runner> TryoutRunners; } class Runner{ private string _fileName; private FileStream _fStream; public void GetStats(){ FileInfo fInfo = new FileInfo(_fileName); _fStream = _fileName.OpenRead(); } }因为Runner集合对于Olympics类是静态的,所以不仅将不释放集合中的对象让它们做垃圾回收(它们全部都是通过roots间接引用),并且您可能已经注意到,每次我们运行GetStats()时,Fileinfo都将打开文件。因为它没有关闭,也没有被GC释放,所以这段代码实际上的运行将是一场等待着发生的灾难。想象一下,我们有1000000个Runner在Olympics中。我们最终将会有许多不可收集的对象,每个对象都有一个开放的资源。
单例模式
保持现状不变的技巧是始终在内存中有一个使用程序类的实例。一种简单的方法就是使用GOF单例模式。应该谨慎的使用单例,因为它们确实是“全局变量”,并且在多线程应用程序中有很多让我们感到头疼和“奇怪”的行为,在这种情况下,不同的线程可能会改变对象的状态。如果我们使用单例模式(或任何全局变量),则我们应该能够证明其合理性。
public class Earth{ private static Earth _instance = new Earth(); private Earth(){} public static Earth GetInstance(){return _instance;} }我们有一个私有的构造函数,因此只有Earth可以执行它的构造函数并制作一个Earth。我们有一个Earth的静态实例和一个获取实例的静态方法。该特定实现是线程安全的,因为CLR确保线程安全地创建静态变量。这是一种优雅的实现单例模式的方法。
结论
我们可以做以下的一些事情来提高GC性能:
- 清理。不要保留资源,确保关闭所有打开的链接,并尽快清理所有非托管对象。作为使用非托管对象的一般规则,请尽可能的延迟实例化并尽快清理。
- 不要过度引用。使用引用对象时候需要合理。请记住,我们的对象如果还活着,那它所引用的所有对象都不会被收集。当我们完成了类所引用的操作后,可以通过将引用设置为null来删除它。还有一个技巧是肩为使用的引用设置为自定义轻量级的NullObject,以避免获取空引用异常。启动GC时候引用到的文件越少,标记过程中的压力就越少。
- 使用finalizer很轻松,但是在GC时候代价却非常的大。我们只能在合理的情况下使用它们。如果我们使用IDisposible而不是finalizer,则效率是非常高的。因为可以通过一次GC就回收掉对象而不需要来两次GC。
- 把object和其子类放在一起。在GC上将大块内存复制到一起比较容易,而不是每次通过堆时都必须对堆进行碎片整理,因此我们声明一个由许多其他对象组成的对象时候,应该将他们尽可能的放在一起实例化。