前言
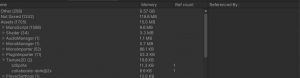
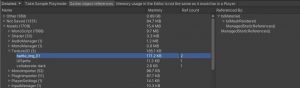
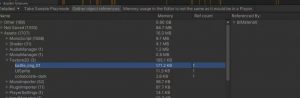
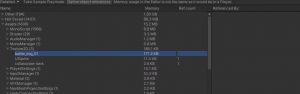
最近公司对于gc考虑的很严格,希望堆上内存只在系统初始化的时候才分配,以减少因为gc导致的cpu卡顿。在这个基础上仔细看了一下值类型的内存分布,了解一下值类型在内存上究竟怎么分配的。
值类型
在定义值类型的变量的时候会直接算好占用多少内存。
public struct DataUnion
{
public long _i64;
public ulong _u64;
public double _f64;
}在定义的时候就已经开辟了24字节的内存保存,就算不存值内存也已经开辟了。
但是他有一个好处就是不会增加gc计算。
public struct DataUnion{
public data _data
}在struct中保存的是引用类型对象的引用,是固定大小的,根据操作系统的位数,32位的占4字节,64位的占8字节。每次传递的时候值类型里的数据都会被复制一份,所以引用也会被拷贝一份。
自定义内存布局方式
通过使用[StructLayout(LayoutKind.Explicit)]和[FieldOffset]特性,这个结构体可以在相同的内存位置上保存多种不同类型的数据,通过这个特性,我们能使用同一个结构保存不同类型的值。
[StructLayout(LayoutKind.Explicit)]
public struct SlateDataBase
{
[FieldOffset(0)]
public long _i64;
[FieldOffset(0)]
public bool _bool;
[FieldOffset(0)]
public ulong _u64;
[fieldOffset(8)]
public string _str;
[FieldOffset(0)]
public IntPtr _next;
}
SlateDataBase _dataBase = new SlateDataBase(){_bool = false};
private SlateDataBase _dataBase1 = new SlateDataBase();
void main(){
IntPtr ptr1 = Marshal.AllocHGlobal(Marshal.SizeOf<SlateDataBase>());
Marshal.StructureToPtr(_dataBase,ptr1,false);
_dataBase1._next = ptr1;
SlateDataBase data = Marshal.PtrToStructure<SlateDataBase>(_dataBase1._next);
data._bool;
}上段代码使用了IntPtr来保存对象指针,这样避免了结构布局中的循环依赖问题。同时通过了StructLayout来控制内存布局。但是我知道有一个问题:
- 如果我分配的内存不是从0开始的,那保存的值会有问题
注意点
- 在使用StructLayout做内存布局的时候是在创建的时候就分配内存了,值类型可相互覆盖,所以都可以从统一位置做偏移,但是引用类型保存的是指针大小,它的大小和对齐方式跟值类型不一样,所以它不能覆盖值类型的内存,得重新取一块内存保存。
- 需要自己手动做InPtr所占内存的回收,而且使用的是指针很容易出内存问题。
- 内存大小是通过最大偏移加类型所占内存。上面所占内存为8字节+string所占(8字节)=16字节
值类型分配地方
一般来说,值类型所分配的地方有两个地方,一个是堆上,一个是栈上。那什么时候分配在堆上,什么时候分配在栈上呢?
public struct SData{
public int _int;
}
public class Data{
public int _int;
public ulong _ulong;
}
public class Data1{
public Data _data;
public SData _sdata;
}
public Data1 _data1 = new Data1();
public void Main(){
SData sdata = new SData();
sdata._int = 10;
_data1._sdata = sdata;
sdata._int = 20;
Data data = new Data();
data._int = 20;
_data1._data = data;
}
上面的示例代码值类型的struct分别在堆和栈上都分配了。
栈上分配:
在函数内创建的sdata是分配在栈上,它的什么周期是跟着函数体的结束而一起结束,内存也就被回收掉了。
堆上分配:
当我实例化了_data1这个引用类型对象的时候,它就在堆上分配了内存,分别是_data的指针大小+_sdata这个struct所占用的内存大小。所以这个时候_sdata是分配在堆上,当我把函数内的
sdata赋值给_sdata的时候,是把sdata的内容给复制过去。所以当我赋值完了之后把sdata的int改成20,实际上_sdata中的_int还是10。
引用类型
在定义引用类型的时候在没有实例化引用类型对象的时候是不会申请内存的。
public class Data{
public long _i64;
}
void main(){
public Data data;
}在使用_i64的时候需要创建一个Data的引用类型对象,相当于对_i64做了一次装箱操作。
当内部保存的类型是引用类型的时候,因为不会出现拷贝引用类型数据,所以引用不会被拷贝。
实例化
当我实例化的时候,就会在堆上分配引用类型中值类型所占用的内存,在堆上分配一个8字节的空间,然后把指针地址返回给data。data就通过这个地址找到这片空间找到里面的_i64所写入的内容。
gc回收
之前说过,不讲了。
泛型类型
根据上面的特性,在构造值类型的泛型时,使用struct来保存
public struct ValueVariable<T> where T : struct{
private T _value;
}
public ValueVAriable<int> _int_value = 10;
public ValueVAriable<bool> _bool_value = false;
这样我在保存一个值类型的时候也是通过值类型保存,所以不会产生gc问题。
引用类型就可以直接使用object来保存。
不安全代码
暂无