前言
最近遇到了怪物在ai寻路的目标点为同一个的时候,会出现相互挤压的情况。所以开始研究群体避障算法。这片文章主要讲一下最基础的VO(Velocity Obstacle)算法。
正文
其实vo算法不是很难的,就是你得实时算它前面是不是会碰到物体,因为是简单的,所以单个物体只管自己的。我先晒一张经典的图
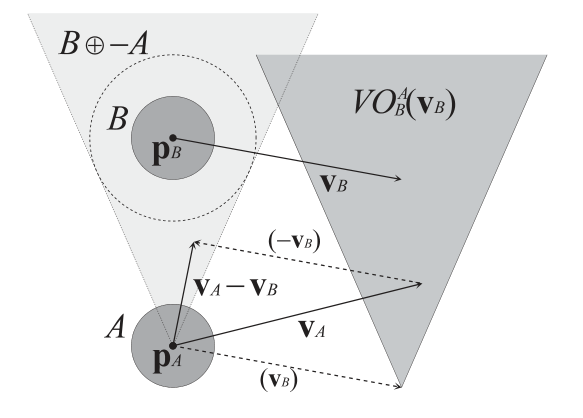
这张图在所以讲vo算法的文章里都会出现的,它直观的展示了vo是怎么算物品之间的碰撞。现在我就基于这个图来详细讲解下相关的知识点。
闵可夫斯基和
在这张图里我们会看到B里有一个实体圈,和一个虚线圈。然后你会发现生成的B⨁−A这个三角形实际上是从A的中心点PA为起点画的,所以可以理解那个虚拟的B圈实际上是把A圈给叠加上了。这里涉及到了一个集合知识点就是闵可夫斯基和(闵氏和)。
概念:两个图形A,B的闵氏和C={a+b|a∈A,b∈B}
其实就是从原点向着图形A内部的每一个点做向量,将图形B沿每个向量移动,最终位置的并集就是闵氏和。
我们来看一个图片吧
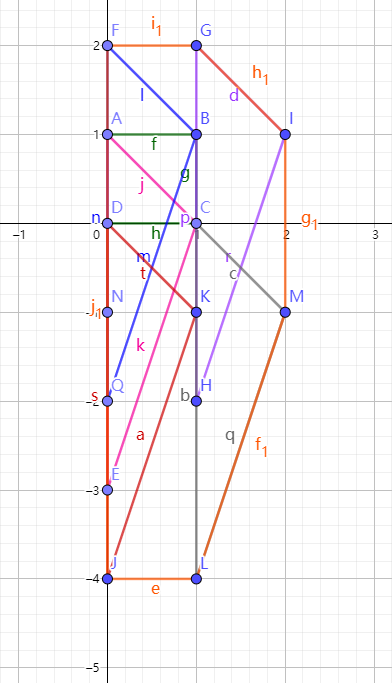
在这张图里a(A,B,C,D)b(A,C,E)。现在我们用它做一个闵氏和,先把b往DA向量方向移动,得到了一个(F,B,Q)这个图型,其他的向量也按这样的移动,我们最后就会得到一个并集成(F,G,I,M,L,J)这个图型。这个图形就是我们要算的a和b的闵氏和。
结合这个知识点,我们现在来看VO的那张图我们就很容易理解了,把B和A放在同一个圆心上,然后沿着圆的四周往外扩散A的半径向量。得到虚框B。
相对位移
当我们A沿着VA移动,B沿着VB移动的时候,我们要确定两个图形是否会碰撞到,因为我们是从a画的一个扇形,所以我们需要计算下A的相对于B的移动向量,这个就用向量相减就好了。算出一个VA-VB的向量,然后我们PA质点沿着VA-VB的方向画一个和B虚框相切的一个图形B⨁−A。因为实际计算不是求的相对速度,是VA的实际速度,所以我们需要加上VB。这样我们就得到了一个深色的三角形。
结论
当我们的速度不属于这个深色三角形内的时候,他们就不会发生碰撞。
补充
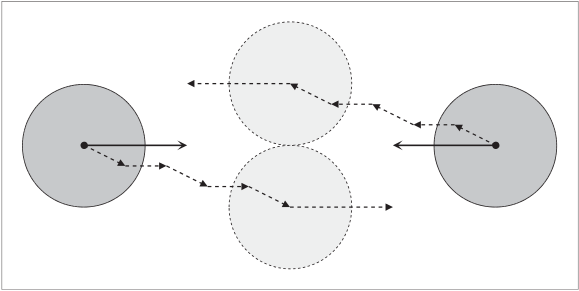
因为VO是把对象都当成一个独立的个体,所以它在计算的时候是实时计算的,当两个物体独立计算的时候,所以他们会单独计算自己的避障速度方向,当A,B沿着避障方向移动的时候,他们在下一次计算会发现自己不在对方的碰撞区域内,所以会修改方向沿着之前会碰撞的方向移动,再下一次计算的时候发现自己又在碰撞区域内了,又开始偏移移动,这样往复以后,就会出现抖动。后面我研究研究VO的优化算法,再讲解下怎么解决这个问题。