前言
在很早之间因为ios和android需要支持arm64位的时候,我就已经在打包的时候接触到了IL2CPP,但是那个时候也就只是为了能打出一个arm64位的包,所以对于它的一些原理都没有去了解过,碰到的一些问题也没有去详细解答,用了最蠢的方式来规避问题,刚好最近也用到了IL2CPP所以在这里记录下,最近对它的一些理解
IL2CPP的前世
首先我们需要知道Unity的跨平台的一些知识点,为啥Unity出的包能在ios和android这两个平台上跑,而我们不需要做啥特殊的操作,只需要在选择出包平台的时候,选对应的打包平台。这是因为在unity会把我们所编写的c#翻译成CIL(公共中间语言),然后再汇编成字节码。
CIL
CIL是一种属于通用语言框架和.NET架构的低阶的人类可读的编程语言,它是有微软公司所提供的。目标是把.NET框架的语言(c#,VB等等)被编译成CIL然后在汇编成字节码。CIL类似一个面向对象的汇编语言,并且它是完全属于堆栈的。它运行在虚拟机上。是一种独立于具体CPU和平台的指令集。然后由JIT编译器转换为特定的计算机环境特定的机械码。这个是在执行CIL之前完成的。它的转换的根据需求转换的,并不是编译整个CIL代码。
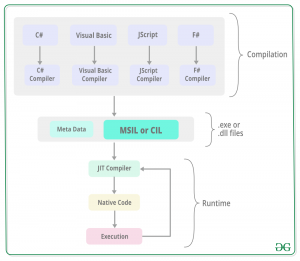
上图展示了CIL的创建和转换为机械码的过程。
- 源代码在CLR的编译时由特定的语言编译器转换为CIL,并且元数据也在这个时候生成。元数据包含代码中类型的定义和签名,运行时信息等内容。
- CIL是一个用于安全,部署,版本控制等编译代码库,它有两种类型,进程程序集(EXE)和库程序集(DLL)。
- JIT编译器将CIL转换为特定与JIT编译器运行的计算机环境的机械代码。按需转换。
- JIT编译器转换的机器代码由计算机处理器执行。
这块内容其实我也没有详细去研究(虽然我买了这本书,但是包装壳还没有拆,等我看完再水一篇)。但是看完上面的这些基础的信息,我们应该对于C#的跨平台有个简单的了解,它通过CIL这个中间语言来打包成程序集,然后再通过JIT来转换到各个平台所能跑的机械码。所以跨平台的重要点就是CIL和解释CIL的编译器。
关键点
但是在ios平台上机器码被禁止映射到内存中,就是不能把JIT实时编译出来的机械码放在一个地方,所以就不能实时在平台上跑CIL的程序集。
所以在这个时候,我们就需要提前做好机器码的编译(AOT)。所以在这个时候,我们打包成功以后,我们在包里的代码就已经变成了机器码了。
Unity中的IL2CPP干了啥
AOT编译器
IL2CPP AOT编译器名为il2cpp.exe。它是由c#编写的受托管的可执行程序,它接受我们在Unity中通过Mono编译器生成的CIL,并把它生成指定平台下的c++代码。
它的工具链如下:
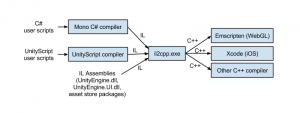
运行时库
它还支持虚拟机的运行时库。几乎都是用c++代码实现的这个库。运行时库的名字叫ilbil2cpp,它作为链接到播放器可执行文件的静态库提供。这个是IL2CPP技术的主要优势,简单且可移植的运行时库。它还有一个关键部分就是垃圾收集器(GC)。使用的是libgc一种BoehmDemers-Weiser垃圾收集器。但是libil2cpp的设计允许我们使用其他垃圾收集器(GC)。
为啥转成CPP呢
-
运行效率快:官方实验数据,换成IL2CPP以后,程序运行效率有了1.5-2.0倍的提升。
-
Mono VM在各个平台移植,维护非常耗时,有时候不可能完成。
-
可以利用现成的在各个平台的c++编译器对代码进行编译期优化,这样可以进一步减少最终游戏的尺寸并提高游戏运行速度。
-
由于去除了IL加载和动态解析的工作,使得IL2CPP VM可以做的很小,并且使游戏载入时间缩短。
脚本限制
System.Reflection.Emit
AOT平台无法实现System.Reflection.Emit命名空间中的任何方法。System.Reflection的其余部分是可接收的。只要编译器可以推断反射使用的代码需要在运行时存在。
序列化
AOT平台可能会由于使用了反射而遇到序列化和反序列化问题。如果仅通过反射讲某个类型或方法作为序列化或反序列化的一部分使用,则AOT编译器无法检测到需要为该类型或方法生成代码。
通用虚拟方法
如果使用泛型方法,编译器必须做一些额外的工作,才能将编写的代码扩展到设备上执行的代码。如果使用虚拟方法,将运行时而不是编译时确定行为,存在虚拟方法时,编译器可在不完成明显的地方轻松要求从源代码生成运行时代码。
从原生代码调用托管代码
需要编组到c函数指针以便可以从原生代码调用的托管方法会在AOT平台上有一些限制:
- 托管方法必须是静态方法。
- 托管方法必须具有[MonoPInvokeCallback]属性
线程
有些平台不支持使用线程,因此任何使用System.Threading命名空间的托管代码都将在运行时失败。此外..NET类库的某些部分存在对线程的隐私依赖。
异常过滤
IL2CPP不支持c#异常过滤器。应该将依赖于异常过滤器的代码修改为正确的catch块。
TypedReference
IL2CPP不支持System.TypedReference类型和__makerefc#关键字
MarshalAs 和 FieldOffset 属性
IL2CPP 不支持在运行时反射 MarhsalAs 和 FieldOffset 属性。它在编译时支持这些属性。应正确使用它们以进行正确的平台调用编组。
动态关键字
IL2CPP 不支持 C# dynamic 关键字。此关键字需要 JIT 编译,而 IL2CPP 无法实现。
代码托管剥离
托管代码剥离将从构建中删除未使用的代码,从而可以显著减小最终构建大小。使用 IL2CPP 脚本后端时,托管代码剥离还可以减少构建时间,因为需要转换为 C++ 并进行编译的代码减少。托管代码剥离将从托管程序集(包括从项目中的 C# 脚本构建的程序集、包含在包和插件中的程序集以及 .NET 框架中的程序集)中删除代码。
托管代码剥离的工作方式是对项目中的代码进行静态分析,检测出在执行过程中永远无法访问的类、类成员甚至函数的某些部分。可以通过 Player Settings 窗口中的 Managed Stripping Level 设置(在 Optimization 部分)来控制 Unity 删除无法访问的代码的激进程度。
重要信息:当代码(或插件中的代码)使用反射来动态查找类或成员时,代码剥离工具不能总是检测出项目是否正在使用这些类或成员,因此可能会删除它们。要声明某个项目正在使用这样的代码,请使用 link.xml 文件或 Preserve 属性。
Unity代码的托管剥离级别设置
使用项目的 Player Settings 中的 Managed Stripping Level 选项来控制 Unity 删除未使用代码的激进程度。
C#所引用的代码剥离
UnityLinker
Unity 构建过程使用一个名为 UnityLinker 的工具来剥离托管代码。UnityLinker 是 Mono IL Linker 的一个定制版本,专为 Unity 设计。UnityLinker 基于我们的项目分叉,此分叉密切跟踪上游 IL Linker 项目。(请注意,该分叉中未维护 UnityLinker 的 Unity 引擎特有自定义部分。)
UnityLinker 的工作方式
UnityLinker 将分析项目中的所有程序集。首先标记顶级、根类型、方法、属性、字段等,例如,向场景中的游戏对象添加的 MonoBehaviour 派生类便是根类型。然后,UnityLinker 分析已标记为要进行识别的根,并标记这些根所依赖的托管代码。完成此静态分析后,所有剩余的未标记代码都无法通过应用程序代码中的任何执行路径来访问,并将从程序集中删除。
请注意,这一过程不会对代码进行混淆处理。
反射和代码剥离
UnityLinker 不能总是检测出项目中的代码通过反射时来引用其他代码的实例,因此可能会误删除实际在使用的代码。将 Managed Stripping Level 设置从 Low 提升为 High 时,代码剥离导致游戏中发生意外行为变化的风险也会增加。这种行为变化小到细微的逻辑变化,大到调用缺失方法造成的崩溃。
UnityLinker 能够检测和处理一些反射模式。如需查看该工具可以处理的最新模式的示例。但是,如果使用的不仅仅是简单的反射,必须给 UnityLinker 一些提示,说明哪些类不应该被处理。可以通过 link.xml 文件和 Preserve 属性的形式提供这些提示:
Preserve 属性 — 直接在源代码中标记要保留的元素。
link.xml 文件 — 声明应如何保留程序集中的元素。
UnityLinker 在分析程序集中未使用的代码时,会将使用属性或 link.xml 文件保留的每个元素视为根元素。
Preserve 属性
在源代码中使用 [Preserve] 属性可防止 UnityLinker 剥离该代码如下属性:
-
Assembly:保留程序集内的所有类型(就好像您为每个类型输入了 [Preserve] 属性一样)。要为程序集分配 Preserve 属性,请将该属性声明放在程序集包含的任何 C# 文件中,但需在所有命名空间声明之外
-
Type:保留类型及其默认构造函数。
-
Method:保留方法、其声明类型、返回类型及其所有参数的类型。
-
Property:保留属性、其声明类型、值类型、getter 方法以及 setter 方法。
-
Field:保留字段、其声明类型和字段类型。
-
Event:保留事件、其声明类型、返回类型、add 方法以及 remove 方法。
-
Delegate:保留委派类型及其所有方法。
请注意,相比使用 Preserve 属性,在 link.xml 文件中标记代码实体可以提供更强的控制。
托管堆栈跟踪
使用发布版本配置时,IL2CPP 可能会生成缺少一个或多个托管方法的调用堆栈。这是因为 C++ 编译器已经内联了缺少的方法。方法内联通常对运行时的性能有好处,但可能会使调用堆栈更难理解。IL2CPP 始终在调用堆栈上提供至少一个托管方法。此方法便是发生异常的方法。调用堆栈上还包括其他未内联的方法。IL2CPP调用堆栈不包含源代码的行号信息,我们需要通过一个叫符号表的文件来对应起来
符号表
其实吧这个东西我也不太清楚是为了什么,网上查到的资料说,这个东西就用来保存函数地址映射信息的中转文件。当程序崩溃的时候,会生成一份崩溃日志,这个日志里所记载的东西就是app出错的函数内存地址,而这些函数地址是可以在符号表中找到具体的文件名,函数名和行号信息。每个app在导出的时候都会生成对应的符号表。
总结
现在我就说说我因为IL2CPP所遇到的一些问题
-
在之前使用pb做配置二进制序列化的时候,因为在反序列化时候,使用了反射的功能,导致在IL2CPP中解析出错,那时候,我没有仔细去研究为啥会出现问题,因为这是第一次升级IL2CPP的版本,所以我很强制的和同事一起写了脚本,把反射的所有方法都给翻译出来,强行当c#脚本调用。
-
在bugly上看崩溃日志的时候,发现在IL2CPP版本中显示的堆栈信息是字符码,不像之前使用MONO一样显示的函数名这样的信息。那时候知道有符号码这样的东西,但是经常上传的符号码和奔溃的版本不匹配,导致解析还是有问题。
-
在含有第三方插件的工程导出的时候,因为少做了一个Link.xml的代码裁剪过滤,导致因为第三方库使用了反射功能使得在IL2CPP的包上出现错误。