基本术语
1.垃圾(Garbage)
就是需要被回收的对象
如果程序可能会直接或者间接地引用一个对象,那么这个对象就被视为“存活”,与之相反的,没有被引用到的就被视为“死亡”。将这些“死亡”对象找出来,然后作为垃圾进行回收,这就是GC的本质。
2.根(root)
就是判断对象是否可被引用的起始点。
至于哪里才是根,不同语言,不同编辑器都有不同的规定,但基本上是将变量和运行栈作为根。
三大基础GC算法
1.标记清除法/标记压缩法
标记清除是最早开发出的GC算法。原理非常简单,首先从根开始将可能被引用的对象用递归的方式进行标记,然后将没有标记到的对象作为垃圾进行回收。
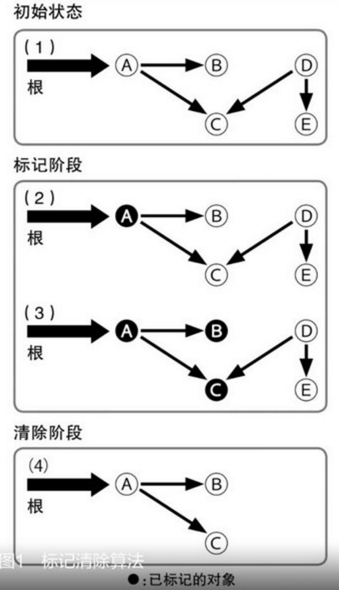
图中显示了标记清除算法的大致原理,1阶段显示了随着程序运行而分配出一些对象的状态,一个对象对其他的对象引用。2阶段开始执行GC操作,从根开始对可能被引用的对象打上“标记”,大多数情况下,这种标记通过对象内部的标志(flag)来实现。3阶段,被标记的对象所引用的对象也打上标记,一直重复这样的操作,就可以把从根开始可能被间接引用到的对象都打上标记。此阶段为标记阶段。
标记阶段完成时,被标记的对象就被视为“存活”对象,4阶段把所有对象都扫描一遍,将没有被标记的对象进行回收,这一阶段为清除阶段。
在扫描的同时,还需要将存活的标记状态清理掉,以便下一次GC操作做好准备,标记清除的消耗时间和存活对象数与对象总数的总和相关。
标记压缩算法,是标记清除算法的变形,他不是将没被标记的对象清除,而是不断压缩。
2:复制收集算法
标记清除算法有一个很大的问题,在分配大量对象的时候,当存活很少一部分的时候,还是需要对全部对象进行一次扫描,就算是不能在用的也要进行扫描,所需要用到的时间大大超过必要值。复制收集算法则试图克服这一问题,在复制收集算法里,会从根结点开始把被引用和间接引用的对象复制到另外一个空间,然后把原空间给回收。
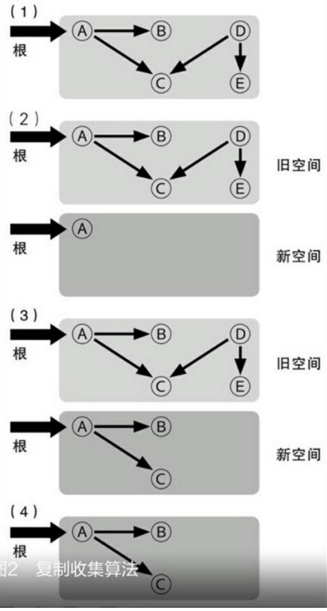
(1)为开始GC时候的内存状态,(2)在原对象空间以外再开辟了一个空间,然后把根引用到的对象(A)给复制过去,(3)把A所引用的对象也给复制过去,递归向下,把所有被根间接引用的对象都复制到新的空间内,而“死亡”对象就还留在旧空间内。(4)回收旧的对象空间,使用新的对象空间。这样就把所有的死亡对象都给释放掉了,留下的还存活的对象。
复制收集对比标记清除中,只有一开始标记的时候是需要递归遍历的,后面标记清除中的扫描所有的对象进行清除这步是不需要的。所有减少了不必要的扫描开销。
但是复制对象的内存开销会比较大,如果存活的对象比较多的情况下,这种算法就十分消耗内存。
还有一个好处就是,关系比较近的对象,可能会放在距离较近的内存空间,可以提高程序运行性能。
3:引用计数法
引用计数方式是GC算法中最简单,也是最容易实现的一种。它的原理:在每个对象中保存该对象的引用计数,当引用发生增减的时候对引用计数进行更新。当引用计数为0的时候,该对象将不被引用,因此可以释放相应的内存空间。
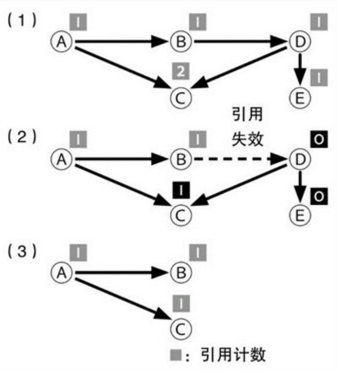
图中(1)部分中,记录着所有对象都保存着自己被多少个其他对象进行引用的数量。(2)中对象引用发生变化时,引用计数也跟着变化。当引用b到d的引用失效,d的引用就为0,将被回收,所以d所引用对象的引用计数也将相应的减少。(3)中对所有引用计数为0的对象进行释放。在这个GC过程中,不需要对所有的对象进行扫描。
在这个GC算法中当对象不被引用的瞬间就会被释放。在其他GC算法中,要预测对象是否能被释放是一个很困难的事,但是在引用计数中,当为0就能被释放了。而且这个释放操作是针对每个对象个别执行的,因此对比其他GC算法,中断时间也比较短。
引用计数最大的缺点就是,不能释放被循化引用的对象
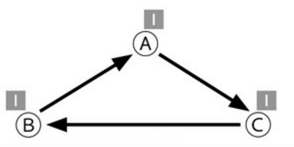
如上图所示,三个对象没有被其他对象所引用,但是相互之间循环引用了。因此它们永远都不会被释放,
还有一个问题就是,必须在引用计数发生变化的时候做出正确的增减,如果出现问题,就会出现内存错误,少加了就会释放过早,多加了就会出现内存泄漏。
最后一个缺点,引用计数管理不适合并行处理,如果多个线程同时对引用计数进行更新,引用计数可能会产生不一致的问题。为了避免这种情况的发生,对引用计数的操作必须采用独占的方式来进行。如果引用操作频繁发生,每次都要使用加锁等并发控制机制的话,其开销也是不可小觑的