GC的前世今生
GC的概念并非才诞生不久,早在1958年,由大名鼎鼎的图灵奖得主john mccarthy所实现的lisp语言就已经提供了GC的功能,这是GC的第一次出现。lisp的程序员认为内存管理太重要的,所以不能由程序员自己来管理。
但是后来的日子里lisp却没有成气候,采用内存手动管理的语言占据了上风,以c为代表。出于同样的理由,不同的人却又不同的看法,c程序员也认为内存管理太重要的,所以不能由系统来管理,并且讥笑lisp程序慢如乌龟的运行速度。的确,在那个对每一个byte都要精心计算的年代GC的速度和对系统资源的大量占用使很多人都无法接受。而后,1984年由dave ungar开发的smalltalk语言第一次采用了Generational garbage collection的技术,但是amalltalk也没有得到十分广泛的应用。
直到20世纪90年代中期GC才以主角的身份登上历史的舞台,这不得不归功于Java的进步,今日的GC已非吴下阿蒙。Java采用VM(virtual machine)机制,由VM来管理程序的运行当然也包括对GC管理。90年代末期.net出现了,.net采用了和Java类似由CLR(Common Language Runtime)来管理。这两大阵营的出现将人们引入了以虚拟平台为基础的开发时代,GC也在这个时候越来越得到大众的关注。
为什么要使用GC呢?也可以说为什么要使用内存自动管理?有以下一个原因:
1. 提高了软件开发的抽象度;
2. 程序员可以将精力集中在实际的问题上而不用分心来管理内存的问题;
3. 可以使用模块的接口更加的清晰,减少模块间的耦合;
4. 大大减少了内存人为管理不当所带来的bug;
5. 使内存管理更加高效。
总的来说就是GC可以使程序员可以从复杂的内存问题中摆脱出来,从而提高了软件开发的速度,质量和安全性。
什么是GC
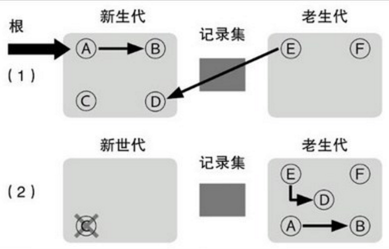
GC就是垃圾收集,这里仅就内存而言。Garbage Collector以应用程序的root为基础,遍历应用程序在Heap上动态分配的所有对象,通过识别它们是否被引用来确定哪些对象是已经死亡的,哪些仍然需要被使用。已经不再被引用程序root引用或者别的对象所引用的对象就是已经死亡的对象,即所谓的垃圾,需要被回收。
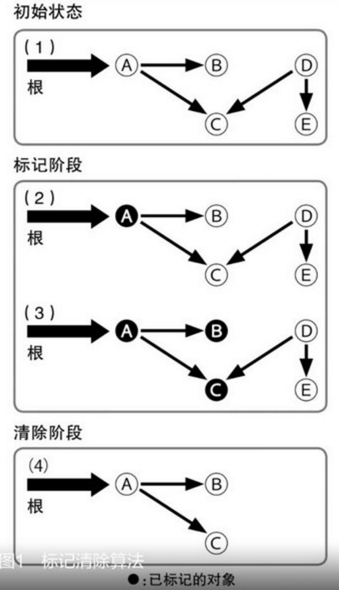
1,Mark-Compact 标记压缩算法
简单的吧.NET的GC算法看作Mark-Compact算法。阶段1:Mark—Sweep 标记清除阶段,先假设heap中所有对象都可以回收,然后找出不能回收的对象,给这些对象打上标记,最后heap中没有打标记的对象都是可以被回收的;阶段2:Compact 压缩阶段,对象回收之后heap内存空间变得不连续,在heap中移动这些对象,使它们重新从heap基地址开始连续排列,提高局部性。
<a href="https://i.loli.net/2019/10/08/TLm9Uy5Kaq2frvF.png"><img src="https://i.loli.net/2019/10/08/TLm9Uy5Kaq2frvF.png" alt="" /></a>
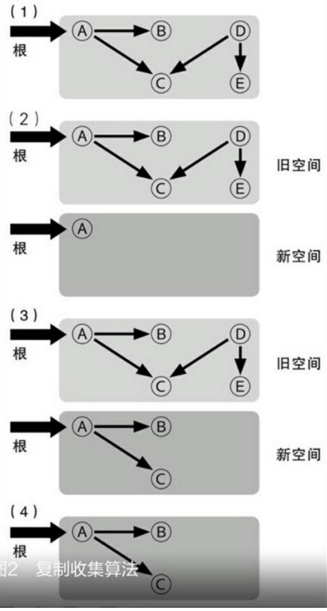
Heap内存经过回收,压缩之后,可以继续采用前面的heap内存分配方法,即仅用一个指针记录heap分配的起始地址就可以。主要处理步骤:将线程挂起->确定roots->创建reachable objects graph->对象回收->heap压缩->指针修复。可以这样理解roots:heap中对象的引用关系错综复杂(交叉引用,循环引用),形成复杂的graph,roots是CLR在heap之外可以找到的各种入口。
GC搜索roots的地方包括全局对象,静态变量,局部对象,函数调用参数,当前CPU寄存器中的对象指针等。主要可以归为两类:已经初始化了的静态变量,线程仍在使用的对象。Reachable objects:指根据对象引用关系,从roots出发可以到达的对象。从roots出发可以创建reachable objects graph,剩余对象即为unreachable,可以被回收。
发现无法访问的对象时,它就使用内存复制功能来压缩内存中可以访问的对象,释放分配给不可访问对象的地址空间块。
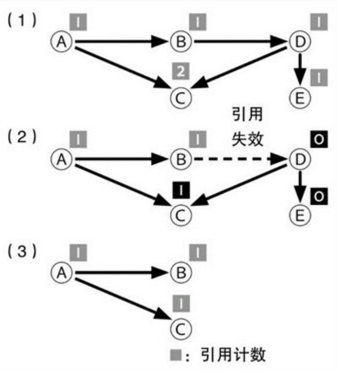
指针修复是因为compact过程中移动了heap对象,对象地址发生变化,需要修复所有引用指针,包括stack,cpu register中的指针以及heap中其他对象的引用指针。传给COM+的托管对象也会成为root,并且具有一个引用计数以兼容COM+的内存管理机制,引用计数为0时,这些对象才可能成为被回收对象。Pinned objects指分配之后不能移动的对象,GC在指针修复时无法修改非托管代码中的引用指针。pinned objects会导致heap出现碎片。
2,托管堆
在垃圾回收器由CLR初始化以后,它会分配一段内存用于存储和管理对象。此内存为托管堆。
每个托管进程都有一个托管堆,进程中的所有线程都在同一个托管堆上为对象分配内存。
堆上分配的对象越小,垃圾回收器必须执行的工作就越少。分配对象时,请勿使用超出你需求的舍入值。
当触发垃圾回收时,垃圾回收器将回收由死对象占用的内存。回收进程会对活动对象进行压缩,以便将它们一起移动,并移除死空间,从而使堆更小一些。这将确保一起分配的对象都位于托管堆上,从而保留它们的局部性。
GC分配两个托管堆:一个用于小型对象(小型对象堆或SOH),一个用于大型对象(大型对象堆或LOH)
对象小于85000字节分配到小型SOH上,大于则分配到LOH上。
触发垃圾回收后,GC将寻找存在的对象并将它们压缩。但是由于压缩成本很高,GC会扫过LOH,列出没有被清除的对象列表以供以后重新使用,从而满足大型对象的分配请求。相邻的被清除对象将组成一个自由对象。
3,代数
虽然对象的生命周期因应用而异,但对于大多数应用来说,大部分的对象在创建不久即变成垃圾。因此针对不同age的对象也就不难理解了。
在.NET垃圾回收器中分三代,0,1,2。
小对象始终在第0代中进行分配,或者根据它们的生存期,可能会提升为第一代或者第二代。
大型对象始终在第二代中分配。
回收一代时,同时也会回收它前面所有代。
用户代码分配只能在SOH中的第0代或LOH中分配。只有GC可以在第一代和第二代中分配对象。
在mono中为写屏障来记录老代对新代的引用。
4,Finalization Queue和Freachable Queue
这两个队列和.NET对象所提供的Finalize方法有关。这两个队列并不用于存储真正的对象。而是存储一组指向对象的指针。当程序中使用new操作符在Managed Heap上分配空间时,GC会对其进行分析,如果该对象含有Finalize方法则在Finalization Queue中添加一个指向该对象的指针。
在GC被启动以后,经过Mark阶段分辨出哪些是垃圾。再在垃圾中搜索,如果发现垃圾中有被Finalization Queue中的指针所指向的对象。则把这个对象从垃圾中分离出来,并将指向它的指针移动到Freachable Queue中。这个过程被称为对象的复生(Resurrecction)。那为什么要救活它呢?因为这个对象的Finalize方法还没有被执行,所以还不能死去。当Freachable Queue中的指针指向的对象执行完Finalize方法以后,这个指针就会从队列中剔除,这个对象就能在下一次GC中被回收了。
.NET Framework的System.GC类提供了控制Finalize的两个方法,ReRegisterForFinalize和SuppressFinalize。前者是请求系统完成对象的Finalize方法,后者是请求系统不要完成对象的Finalize方法。ReRegisterForFinalize方法其实就是将指向对抗的指针重新添加到Finalization Queue中。如果在对象的Finalize方法中调用ReRegisterForFinzlize方法,这样就会形成一个在堆上永远不会死去的对象。
5,弱引用
如果应用程序代码访问一个正由该程序使用的对象时,垃圾回收器就不能回收该对象,那么就认为这个应用程序对该对象有强引用。
弱引用允许应用程序访问对象,同时也允许垃圾回收器收集相应的对象。如果不存在强引用,则弱引用的作用时间只限于收集对象前的一个不确定时间段。使用弱引用时,应用程序仍可以对该对象进行强引用,这样做可防止该对象被收集。但始终存在这样的风险:垃圾回收器在重新建立强引用之前先处理改对象。
若要对某对象建立弱引用,请使用要跟踪的对象实例创建WeakRefernce。然后将Target属性设置为该对象,将该对象的原始引用设置为null。
aa a = new aa();
a.a = 2;
WeakReference c = new WeakReference(a);
a = null;
GC.Collect();
Console.WriteLine(c.Target != null);
Console.WriteLine(c.IsAlive);
Console.WriteLine(c.Target);
/*
延时执行if判断的时候,c.Target是为null的
var t1 = Task.Run(async delegate { await Task.Delay(5000); if (c.IsAlive)
{
}
});
*/
/*
这段代码如果执行的话,在上一个GC期间c.Target是不为Null的,但是如果不执行的话,c.Target是null
if (c.IsAlive)
{
}
*/
GC.Collect();
/*
在GC调用完以后c.target为null。
*/
Console.WriteLine(c.IsAlive);
Console.ReadKey();
WeakRefernce也是一个引用对象,当这个对象也在被引用的时候,期内部的target是不会被回收的。
短弱引用和长弱引用
- 短弱引用:
垃圾回收功能回收对象后,短弱引用的目标将会变成null。弱引用本身是托管对象,与其他任何托管对象一样需要经过垃圾回收。 - 长弱引用:
在对象的Finalize方法已调用后,长弱引用获得保留。这样,便可以重新创建该对象,但该对象仍保持不可预知的状态,仍然可能在下一次的GC中被回收掉。若要使用长弱引用,请在WeakReference构造函数中指定true。
如果对象类型不包含Finalize方法,或者Finalize方法没有被执行(调用了GC.SuppressFinalize();),那么将被应用为短弱引用。弱引用只在目标被收集前有效,运行终结器后可以随时收集目标。
如果要建立强引用并重新使用对象,请将WeakReference的Target属性强行转换为对象类型。使用前请先判断Target是否为null。