前言
在研究了一段时间的GC后,发现自己使用的两种语言,lua和c#的GC实现分别是两种高级GC算法,一个是增量式,一个是分代式。前者是标记清除,后者是标记压缩。
luaGC
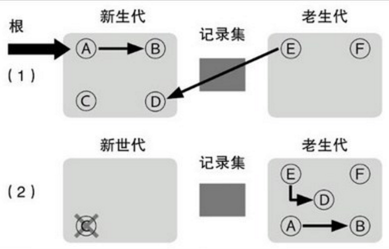
在lua中,GC为标记清除增量式的,系统管理着所有已经创建了的对象,每个对象都有对其他对象的引用。root集合代表着已知的系统级别的对象引用。我们从root出发,就可以访问到系统引用到的所有对象。而没有被访问到的对象就是垃圾对象,需要被销毁。
三色垃圾回收
在GC中我们把所有的对象分为三个状态:
1. White状态,也就是待访问状态。表示对象还没有被垃圾回收的标记过程访问到。
2. Gray状态,也就是待扫描状态。表示对象已经被垃圾回收标记过程访问到了,但是对象本身对于其他对象的引用还没有进行遍历访问
3. Black状态,也就是已扫描状态。表示对象已经被访问到了,并且也已经遍历了对象本身对其他对象的引用。
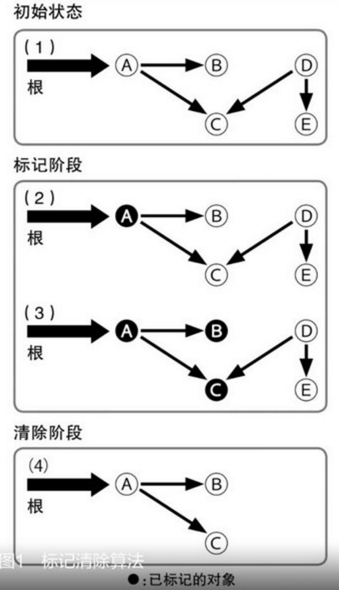
基本的算法可以描述如下:
当前所有对象都是White状态;
将root集合引用到的对象从White设置成Gray,并放到Gray集合中;
while(Gray集合不为空)
{
从Gray集合中移除一个对象0,并将0设置成Black状态;
for(0中每一个引用的对象01){
if(01在White状态){
将01从White设置成Gray,并放到Gray集合中;
}
}
}
for(任意一个对象0){
if(0在white状态)
销毁对象0;
else
将0设置成White状态;
}
Increment Garbage Collection
上面的算法如果一次性执行,在对象很多的情况下,会执行很长时间,严重影响程序本身的响应速度。其中一个解决办法:把上面的算法分步执行,这样每个步骤所消耗的时间就比较小了。我们可以将上述的算法改为以下几个步骤。
首先标示所有root对象:
1. 当前所有对象都是White状态;
2. 将root集合引用到的对象从White设置成Gray,并且放在Gray集合中。
遍历访问所有gray对象。如果超出了本次计算量上限,退出等待下一次遍历:
while(Gray集合不为空,并且没有超出本次计算量的上限){
从Gray集合中移除一个对象0,并将0设置成Black状态;
for(0中每一个引用到的对象01){
if(01在White状态){
将01从White设置成Gray,并放到Gray集合中;
}
}
}
销毁垃圾对象:
for(任意一个对象0){
if(0在White状态)
销毁对象0;
else
将0设置成White状态;
}
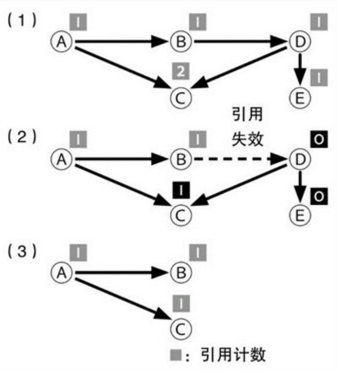
在每个步骤之间,由于程序可以正常执行,所以会破坏当前对象之间的引用关系。black对象表示已经被扫描的对象,所以他应该不可能引用到一个white对象。当程序的改变使得一个black对象引用到一个white对象时,就会造成错误。解决这个问题的办法就是设置barrier。barrier在程序正常运行过程中,监控所有的引用改变。如果一个black对象需要引用一个white对象,存在两种处理办法:
1. 将white对象设置成gray,并添加到gray列表中等待扫描。这样等于帮助整个GC的标示过程向前推进了一步。
2. 将black对象改成gray,并添加到gray列表中等待扫描。这样等于使整个GC的标识过程后退了一步
这种回收垃圾回收方式被称为“Incremental Garbage Collection”(简称“IGC”)lua所采用的就是这种方法。使用“IGC”并不是没有代价的。IGC所检测出来的垃圾对象集合比实际的集合要小,也就是说,有些在GC过程中变成垃圾的对象,有可能在本轮GC中检测不到。不过这些残余的垃圾对象一定会在下一轮GC被检测出来,不会造成泄漏。
GCObject
lua使用union GCObject来表示所有的垃圾回收对象:
union GCObject{
GCheader gch;
union TString ts;
union Udata u;
union Closure cl;
struct Table h;
struct Proto p;
struct UpValue uv;
struct lua_state th;
}
#define CommonHeader GCObject *next;lu_byte tt;lu_byte marked
typedef struct GCheader {
CommonHeader;
}GCheader;
marked这个标志用来记录对象与GC相关的一些标志位,其中0和1用来表示对象的white状态和垃圾状态。当垃圾回收的标识阶段结束后,剩下的white对象就是垃圾对象。由于lua并不是立即清除这些垃圾对象,而是一步一步逐渐清除,所以这些对象还会在系统中存在一段时间。这就需要我们能够区分同样为white状态的垃圾对象和非垃圾对象。lua使用两个标志位来表示white,就是为了高效的解决这个问题。这个标志位会轮流被当作white状态标志,另一个表示垃圾状态。在global_Static中保存着一个currentwhite,来表示当前是哪个标志位用来标识white。每当GC标识阶段完成,系统会切换这个标志位。这样原来为white的所有对象不需要遍历就会变成垃圾对象,而真正的white对象则使用新的标志位标识。
第二个标志位用来表示black状态,而既非white也非black也就是gray状态。
除了short string 和open upvalue之外,所有的GCObject都是通过next被串接到全局状态global_State中的allgc链表上。我们可以通过遍历allgc链表来访问系统中的所有GCObject,short string 被字符串标单独管理,open upvalue会在被close时也连接到allgc上。
引用关系
垃圾回收过程通过对象之间的引用关系来标识对象。以下是lua对象之间在垃圾回收标识过程中需要遍历的引用关系:

所有字符串对象,无论长串还是短串,都没有对其他对象的引用。
uesdata对象会引用到一个metatable和一个env table。
Upval对象通过v引用一个TValue,再通过这个TValue间接引用一个对象。在open状态下,这个v指向stack上的一个TValue。在close状态下,v指向Upval自己的TValue。
table对象会通过key,value引用到其他对象,并且如果数组部分有效,也会通过数组部分引用。并且table会引用一个metatable对象。
lua closure会引用到proto对象,并且会通过upvalue数组引用到Upval对象。
c closure会通过upvalues数组引用到其他对象,这里的upvalue与lua closure的upvalue完全不是一个意思。
Proto对象会引用到一些编译器产生的名称,常量,以及内嵌于本Proto中的Proto对象。
thread对象通过stack引用其他对象
barrier
在igc的mark阶段,为了保证所有black对象都不会引用white对象这个不变性,需要使用barrier。
barrier被分为“向前”和“向后”两种。
luaC_barrier_函数用来实现“向前”的barrier。“向前”的意思是当一个black对象需要引用一个white对象时,立刻mark这个white对象。这样white对象就变成gray对象,等待下一步的扫描。这也就是帮助GC向前标识一步。luaC_barrier_函数被用在以下引用变化处:
- 虚拟机执行过程中或者通过api修改close upvalue对其他对象的引用
- 通过api设置userdata或table的metatable引用
- 通过api设置userdata的env table引用
- 编译构建proto对象过程中proto对象对其他编译产生对象的引用
luaC_barrierback_函数用来实现“后退”的barrier。“向后”的意思就是当一个black对象引用一个white对象时,将已经扫描过的black对象再次变成gray对象,等待重新扫描。这也就是把gc的mark后退一步。luaC_barrierback_目前只用来监控table的key和value对象引用的变化。table是lua中最主要的数据结构,练全局变量都是被保存在一个table中,所以table的变化是比较频繁的。并且同一个引用可能被反复设置成不同的对象。对table的引用使用“向前”的barrier,逐个扫描每次引用变化的对象,会造成很多不必要的消耗。而使用“向后”的barrier就等于将table分成了“未变”和“已变”两种状态。只要一个table改变了一次,就将它变成gray,等待重新扫描。被变成gray的table在被重新扫描之前,无论引用再发生多少次变化也都无关紧要了。
引用关系变化最频繁的要数thread对象了。thread通过stack引用其他对象,而stack作为运行期栈,在一直不停地被修改。如果要监控这些引用变化,肯定会造成执行效率严重下降。所以lua并没有在所有的stack引用变化处加入barrier,而是直接假设stack就是变化的。所以thread对象就算被扫描完成,也不会被设置成black,而是再次设置成gray,等待再次扫描。
Upvalue
Upvalue对象在垃圾回收中的处理是比较特殊的。
对于open状态的upvalue,其v指向的是一个stack上有TValue,所以open upvalue与thread的关系非常紧密。引用到open upvalue的只可能是其从属的thread,以及lua closure。如果没有lua closure引用这个open upvalue,就算他一定被thread引用着,也已经没有实际意义了。应该被回收掉。也就是说thread对于open upvalue的引用完全是一个弱引用。所以lua没有将open upvalue当作一个独立的可回收对象,而是将其清理工作交给从属的thread对象来完成。在mark过程中,open upvalue对象只使用white和gray两个状态,来代表是否被引用到。通过上面的引用关系可以看到,有可能引用open upvalue的对象只可能被lua closure引用到。所以一个gray的open upvalue就代表当前有lua closure正在引用它,而这个lua closure不一定在这个thread的stack上面。在清扫阶段,thread对象会遍历所有从属自己的open upvalue。如果不是gray,那就说明没有lua closure引用这个open upvalue,可以被销毁。
当退出upvalue的语法域或者thread被销毁,open upvalue会被close。所有close upvalue与thread已经没有弱引用关系,会被转化为一个普通的可回收对象,和其他对象一样进行独立的垃圾回收。
__GC
对于lua5.0以后的版本支持userdata,它是可以带有__gc方法,当userdata被回收时会调用这个方法。所以一遍标记是不够的。不能简单的把变成垃圾的userdata简单剔除,那样就无法正确的调用__gc了。所以标记流程需要分两个阶段做。第一阶段把包括userdata在内的死亡对象剔除出去。然后在死对象中找回有__GC方法的,对它们再做一次标记复活相关的对象,这样才能保证userdata的__gc可以正确运行。执行完__gc的userdata最终会在下一轮gc中释放(如果没有在__gc中复活)。userdata有一个单向标记,标记__gc方法是否有运行过,这可以确保userdata的__gc只会执行一次,即使在__gc中复活(重新被root集合引用),也不会再次分离出来反复运行finalizer。也就是说,运行过finalizer的userdata就永久变成了一个没有finalizer的userdata了。